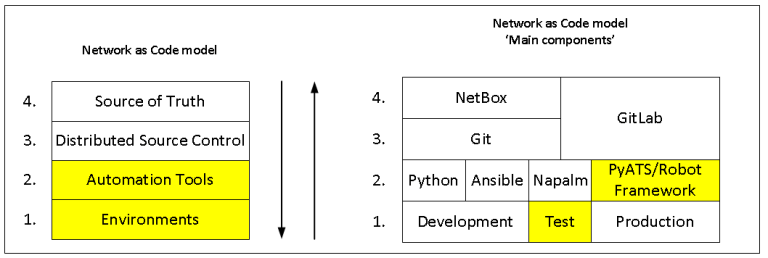
Greetings!
In this post, I want to show a video that contains the example of network automation tests using ‘PyATS framework’ which checks NTP server on certain devices in ‘test environment’ and if NTP server is not correct does auto-rollback on one step back.
More details about ‘TS-1 example’ under the video in this post.
Timestamps are inside the video.
If you have not read the ‘Introduction’ post, it is a good starting point to understand what I will talk about.
This simple TS example shows how network automation tests can be used to detect problems in the network and automatically rollback the configuration to a step back if the test is not successful.
Difficulties
Since the virtual network of the fictitious company ‘X’ has multi-vendor devices each Network OS does a ‘rollback’ and ‘NTP check’ in its own way and everything is not that simple.
In this example, I used devices:
HQ-FW (Cisco ASAv), HQ-ED1 (Cisco IOSv), vSRX-BR2-FW1 (JunOS) and VyOS-BR1-ED1 (VyOS)
Network OSs such as ‘Cisco ASA’ and ‘VyOS’ require a ‘reboot’ to rollback the configuration.
Of course, you can use the ‘no ‘ for Cisco ASA and ‘delete ‘ for VyOS commands and then you do not need to reboot the device, but because the configuration for the devices is generated locally and then have sent to the devices in automatic mode (using a robot (Docker-runner on GitLab), the manual changes of configurations will take a lot of time.
For small changes, the manual changes are well suited, but when the changes are very large that is another story.
It always depends on …
To understand the difference between the new locally generated configuration and the configuration on the device, using Ansible module ‘napalm_install_config’ which makes life easier for Network Engineers.
But there are always exceptions,
Cisco ASA does not support that module, so I use the python (Netmiko) script in conjunction with the ‘napalm_install_config’ in one Ansible playbook.
That python script sends the generated configuration from the ‘config file’ to the device, previously made a backup (locally to the “flash:\“) for a subsequent rollback (if necessary), but it does not show the difference between the newly generated local configuration and the configuration on the device. This can be done, but it will take a lot of time, so this is for Future directions.
Here I gave an example about Ansible/NAPALM, https://www.netascode.com/?p=369
And here, a full video demonstration, https://www.netascode.com/?p=501
I think that if problems arise after installing a new configuration and something has badly broken so that is better to go back to calmly investigate the problem.
But sometimes, on the contrary, you need to collect as much information as possible after the problem happened in order to understand what is broken.
For example, It is possible to create the ‘GitLab pipeline’ that after sending changes to devices (of course, unless remote access is not lost), firstly network tests will collect various information about all services or only specific ones, then make an archive for further investigation. After that network tests will perform (which may contain the rollback process of the configuration if the test/s was not successful) or a separate pipeline stage for the manual rollback of configuration.
Here needs to analyze and understand when and what is better to use.
Also, another difficulty is to write one common test for returning the configuration at least one step back and when a business has network devices from different vendors which have different working logic and etc. and when the changes need to be made simultaneously on a large number of devices.
In this example from the video above, I used a simple rollback logic that contains only two states of the configuration:
‘Rollback 0 (Active)’ — the current configuration on the device.
‘Rollback 1 (Standy)’ — the previous configuration.
The following picture describes that process:
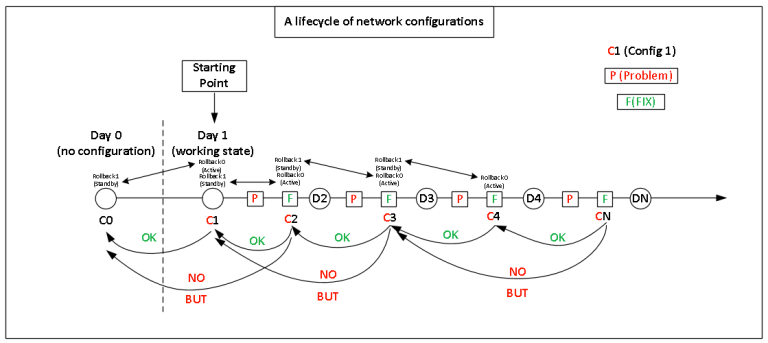
The Day 1 – is the starting point for countdown of configurations that is the day when the network has an operational (working) state. Further, if there are network problems or updates/changes they will be documented in ‘GitLab’ to keep track of all changes.
For example, between the first (D1) and the second (D2) days, a problem appears in the network. The first step is to create ‘GitLab Issue’ (with a description of the problem than to create a new branch).
In a new branch, the Network Engineer corrects/modifies/adds/tests a new configuration in the ‘development’ environment which will be sent to the devices, firstly to the ‘test environment’ and then to ‘prod using GitLab CI/CD. If the changes are completed successfully (merge to the master branch will occur). Thus, the configuration number becomes ‘C2’.
From this point, ‘automatically’ can only go one step back to ‘C1’ (before any new changes), but you cannot go back, for example, to ‘C0’ because only two states of configurations have existed ‘Rollback 0’ and ‘Rollback 1’ (in my example).
‘BUT’ – means that since GitLab tracks all changes, you can view and restore the previous configuration, but in manual mode.
Of course, you can make an automatic backup in one place to be able to return to any point in time, but how to automate it that is a challenge.
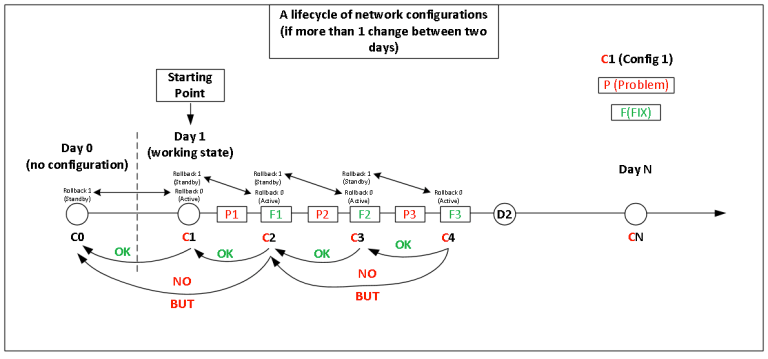
The following picture shows, if there are many problems and corrections, between the first and second days:
P. S. At the end of the project, I will make my GitHub repository public that where the project files are located (startup configurations, ansible playbooks, docker-compose.yml and etc.)